
L’essentiel à retenir : maîtriser les balises noindex et nofollow permet de piloter précisément ce que Google affiche ou ignore. En utilisant le noindex pour masquer vos pages privées et le nofollow pour protéger votre autorité SEO, vous optimisez votre budget de crawl. Attention : ne bloquez jamais une page noindex via le robots.txt, sinon Google ne verra pas l’ordre de désindexation.
Avez-vous déjà eu cette sensation désagréable de voir une page privée ou un brouillon technique apparaître dans les résultats de recherche de Google ? Je vous rassure, maîtriser le duo nofollow noindex permet justement de reprendre les commandes de votre visibilité en indiquant précisément aux robots quels contenus ignorer ou ne pas suivre. Dans ce guide, je vous explique comment utiliser ces instructions simples pour protéger votre autorité SEO et garantir que seuls vos meilleurs contenus captent l’attention des internautes.
- Pourquoi maîtriser les balises noindex et nofollow est vital pour votre SEO
- Comment installer correctement ces directives sur votre site
- 3 combinaisons gagnantes pour piloter les robots de Google
- Les erreurs classiques qui bloquent votre visibilité
Pourquoi maîtriser les balises noindex et nofollow est vital pour votre SEO
Gérer la visibilité de votre site demande de la précision. On va voir ensemble comment orienter les robots pour que seules vos pages stratégiques brillent dans les résultats.
La différence entre exploration et indexation expliquée simplement
Le crawl correspond au passage des robots sur vos URL. C’est la phase de découverte où Google parcourt votre code pour identifier chaque contenu disponible.
Découvrir une page ne signifie pas l’intégrer. L’indexation est l’étape suivante, où le moteur décide de stocker vos informations dans sa base de données.
Une page explorée peut rester invisible. L’indexation est une décision algorithmique délibérée, pas un simple automatisme technique après le passage du robot de recherche.
Comprendre ce distinguo change tout. On ne gère pas le crawl comme l’indexation.
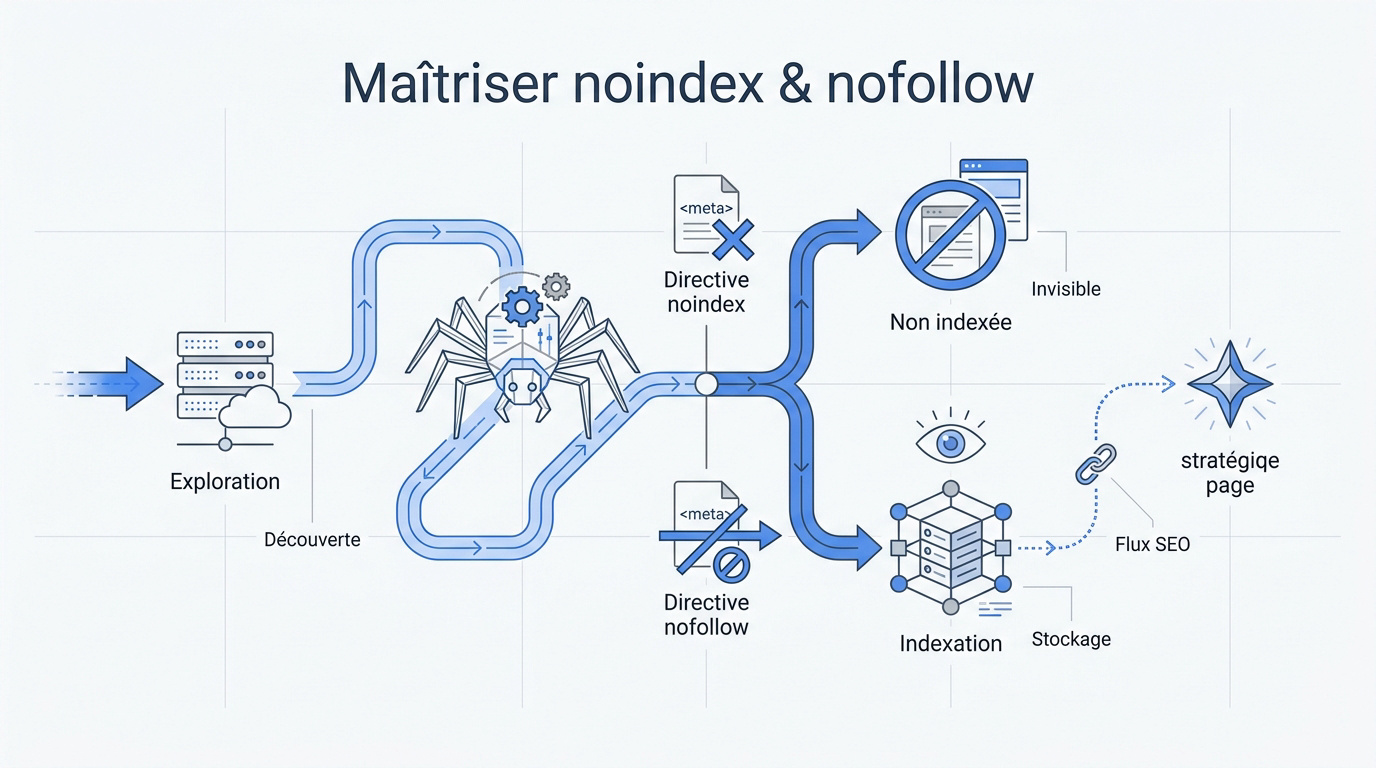
Le rôle précis du noindex et du nofollow dans votre stratégie
Le noindex est un ordre de retrait formel. C’est une directive radicale pour protéger vos pages de test ou vos contenus privés. Je l’utilise pour nettoyer les résultats.
Le nofollow coupe la transmission de popularité. En indiquant aux robots de ne pas suivre un lien, vous préservez votre jus SEO. C’est idéal pour indexer un site WordPress efficacement.
Moins de pages inutiles indexées libère de l’espace. Votre budget de crawl est mieux utilisé sur vos pages stratégiques.
Comment installer correctement ces directives sur votre site
Maintenant que les concepts sont clairs, passons à la mise en œuvre technique concrète dans le code ou via vos outils habituels.
L’insertion des balises meta dans le code HTML de vos pages
Insérez la balise meta name= »robots » dans la section head de votre code. C’est l’emplacement universel reconnu par tous les navigateurs web. Je vous conseille cette méthode simple.
Vous pouvez aussi cibler spécifiquement Googlebot au lieu des robots globaux. Cela permet de donner des ordres précis à certains moteurs uniquement. C’est très pratique.
Pour une page privée, utilisez la syntaxe « noindex, nofollow ». Ce duo assure un verrouillage total de votre contenu. Vos données restent ainsi bien à l’abri.
Utiliser le X-Robots-Tag pour vos fichiers PDF et images
L’usage des en-têtes HTTP est indispensable pour vos fichiers non HTML. On configure cela directement sur le serveur pour vos PDF. C’est une manipulation technique mais redoutable.

Détaillez bien cette configuration pour vos documents techniques. Cela évite que vos précieuses notices internes ne polluent les résultats publics. On protège ainsi votre savoir-faire.
Pensez aussi à protéger vos ressources visuelles. Les images sensibles ne doivent pas apparaître dans Google Images. C’est la clé pour garder le contrôle total.
Gérer les réglages directement depuis votre CMS habituel
Les CMS proposent souvent des options natives très intuitives. Parfois, une simple case à cocher suffit pour gérer l’indexation. Je vais vous simplifier la vie.
Utilisez des extensions comme Yoast ou Rank Math. Ces outils automatisent le marquage proprement sans erreur technique. C’est un gain de temps énorme pour votre activité.
Cela simplifie la gestion pour vous, entrepreneurs. Pas besoin de toucher au code pour rester maître de votre site. Vous gardez la main facilement.
3 combinaisons gagnantes pour piloter les robots de Google
Au-delà de l’installation, le secret réside dans le choix de la bonne combinaison selon vos objectifs de visibilité.
Choisir entre noindex, follow et noindex, nofollow selon l’usage
Parlons de vos pages de pagination. On veut souvent que Google suive les liens sans indexer la page elle-même. C’est ici qu’intervient le « noindex, follow ».
Laisser les robots circuler est malin. Cela permet de découvrir vos articles profonds via des catégories cachées. C’est une stratégie subtile mais payante. Le jus circule sans polluer l’index.
Parfois, il faut tout bloquer. Pour une page de remerciement, le « noindex, nofollow » s’impose naturellement.
- Cas d’usage noindex/follow : pagination des articles, filtres de produits.
- Cas d’usage noindex/nofollow : pages de remerciement (thank you pages), interface admin.
- Cas d’usage index/nofollow : liens d’affiliation présents sur une page publique.
Pourquoi la balise canonical est parfois une meilleure alliée
Le noindex supprime purement la page des résultats. À l’inverse, la balise canonical suggère une version officielle à Google. C’est une approche bien plus souple.
Elle permet surtout de fusionner votre force SEO. La balise canonical transfère l’autorité vers votre page principale. On ne perd ainsi aucune puissance de lien.
Je vous conseille la sécurité pour vos boutiques. Pour des fiches produits similaires, préférez toujours la canonical au noindex.
Les erreurs classiques qui bloquent votre visibilité
Attention toutefois, car une mauvaise manipulation peut ruiner vos efforts ou laisser des pages indésirables.
Le piège du robots.txt qui empêche la désindexation
Le conflit majeur survient souvent ici. Si votre robots.txt bloque l’accès, Google ne peut pas lire votre balise noindex. Résultat ? La page reste indexée malgré vos ordres.
Il faut d’abord résoudre ce problème de priorité. Laissez la page accessible pour que le robot voie l’ordre de désindexation. C’est une erreur de débutant fréquente. Soyez vigilant sur ce point précis.
Voici l’ordre logique. Autorisez le crawl, insérez le noindex, puis attendez la disparition. Bloquez ensuite via le robots.txt si nécessaire.
Ma page est toujours sur Google : comment vérifier le tir
Utilisez la Search Console pour le diagnostic. L’outil d’inspection d’URL vous dira exactement ce que Google voit. C’est votre juge de paix pour comprendre l’état réel.

Besoin d’un retrait urgent ? Utilisez l’outil de suppression de la console. Pour un contenu sensible, c’est immédiat. Attention, cela reste une solution temporaire en cas de crise.
Vérifiez enfin la prise en compte des changements. Les robots ne repassent pas instantanément sur votre site. Soyez patient après avoir corrigé vos balises meta manuellement.
| Problème constaté | Cause probable | Solution technique |
|---|---|---|
| Page toujours indexée | Blocage robots.txt actif | Supprimer le Disallow temporairement |
| Erreur de crawl | Accès serveur restreint | Vérifier les permissions du serveur |
| Perte de PageRank | Nofollow appliqué partout | Utiliser le nofollow avec parcimonie |
| Fichier PDF visible | Absence de X-Robots-Tag | Ajouter noindex dans l’en-tête HTTP |
Maîtriser ces instructions de non-indexation et de non-suivi des liens est essentiel pour protéger votre budget de crawl et valoriser vos pages stratégiques. Appliquez dès maintenant ces réglages sur vos contenus privés pour assainir votre visibilité. Un pilotage précis du nofollow noindex transforme durablement la performance de votre site !
FAQ
Quelle est la différence concrète entre les balises noindex et nofollow ?
C’est une question que mes clients me posent souvent ! Pour faire simple, la balise noindex est un ordre formel que vous donnez aux moteurs de recherche pour ne pas afficher une page dans les résultats. C’est l’outil idéal pour cacher vos pages de test ou vos contenus privés.
Le nofollow, lui, agit sur les liens. Il indique aux robots de ne pas suivre les pistes présentes sur la page. On l’utilise pour ne pas transmettre votre précieux « jus SEO » à des sites tiers ou pour signaler des liens sponsorisés. En résumé : l’un cache la page, l’autre coupe le fil conducteur vers d’autres contenus.
Comment puis-je mettre une page en noindex sur mon site ?
Il existe plusieurs méthodes selon votre aisance technique. La plus courante consiste à insérer une petite ligne de code, la balise meta name= »robots » content= »noindex », directement dans la section <head> de votre page HTML. Si vous voulez cibler uniquement Google, vous pouvez préciser « googlebot » à la place de « robots ».
Pour ceux qui utilisent des CMS comme WordPress, c’est encore plus simple ! Des extensions comme Yoast SEO ou Rank Math vous permettent de cocher une case pour désindexer une page sans jamais toucher au code. C’est un gain de temps précieux pour rester maître de votre visibilité.
Pourquoi ma page apparaît-elle encore sur Google malgré ma balise noindex ?
C’est le piège classique ! Souvent, la cause vient du fichier robots.txt. Si vous bloquez l’accès à une page dans ce fichier, les robots de Google ne peuvent même pas la parcourir. Résultat : ils ne voient jamais votre consigne « noindex » et la page peut rester dans l’index si elle est liée par d’autres sites.
Ma recommandation est simple : laissez d’abord la page accessible au crawl pour que Google lise la directive noindex. Une fois que la page a disparu des résultats de recherche, vous pourrez alors, si besoin, bloquer son accès via le robots.txt. La patience est votre meilleure alliée ici !
Peut-on utiliser le noindex pour des documents comme les PDF ?
Absolument, et c’est même très recommandé pour vos documents internes ou vos notices techniques ! Comme un PDF n’a pas de section <head> pour y placer une balise HTML, on utilise ce qu’on appelle le X-Robots-Tag.
Il s’agit d’une instruction configurée directement au niveau de votre serveur (dans l’en-tête HTTP). Cela permet d’indiquer aux moteurs de recherche que ce fichier spécifique ne doit pas être indexé. C’est la solution parfaite pour protéger vos ressources visuelles ou vos documents de travail d’une exposition publique non souhaitée.
Est-ce que le nofollow garantit que Google ne suivra jamais mon lien ?
Depuis septembre 2019, Google a un peu changé les règles du jeu. Désormais, le nofollow (tout comme les nouveaux attributs rel= »sponsored » ou rel= »ugc ») est considéré comme un « « indice » plutôt que comme une règle absolue.
Cela signifie que Google se réserve le droit de suivre le lien s’il juge cela pertinent pour comprendre la structure du web. Cependant, dans la grande majorité des cas, cela reste le meilleur moyen de protéger votre autorité SEO et de signaler la nature de vos liens sortants.






